library(tidyverse)
library(readr)
library(ggplot2)
library(forcats)
library(tidytext)MCA Anaylse Beläge
MCA Anaylse für Szenario 0 bis 3
Ziel: Wahl der besten drei Beläge nach MCA Berechnung
Szenario 0: “Baseline (IST-Analyse)”: Simuliert die aktuellen Projektanforderungen (deir IST-Analyse). Der Fokus liegt primär auf Wirtschaftlichkeit (insb. kosten) und hoher Nutzungsqualität (insb. befahrbarkeit und barrierefreiheit). Ökologische Aspekte sind sekundär.
Szenario 1: “Forschungsfokus”: Bildet meine zentrale Forschungsfrage (FQ) ab. Dieses Szenario sucht die Balance zwischen den beiden Hauptsäulen meiner Arbeit: dem Lebenszyklus-Fokus (H1/H2) und dem Vermeidungsprinzip (H3).
Szenario 2: “Radikale Vermeidung”: Testet Hypothese 3 (H3) im Extrem. Es priorisiert radikal die Kriterien des Vermeidungsprinzips, also Umweltbelastung (co2, graueEnergie) und Kreislauffähigkeit (recyclingfaehigkeit, modulareErneuerbarkeit).
Szenario 3: “Radikaler Lebenszyklus”: Testet die Hypothesen 1 und 2 (H1/H2) im Extrem. Es priorisiert radikal die Kriterien der Langlebigkeit & Wirtschaftlichkeit (insb. lebensdauer und unterhalt), um die Anzahl der Sanierungs-Eingriffe über den Zeitstrahl zu minimieren.
Libraries laden
1. Daten Importieren
Einlesen der Rohdaten für Belaege und Gewichtung für Szenario 0 bis 3
## 1. Daten Importieren
# Liest die Rohdaten für die Beläge ein
df_belaege_raw <- read_delim(
"01_data_input/Belaege_normiert.csv",
delim = ";"
)
# Liest die Gewichtungen für alle vier Szenarien ein
weights_s0_raw <- read_delim(
"01_data_input/Belaege_Gewichtung_Szenario0.csv",
delim = ";"
)
weights_s1_raw <- read_delim(
"01_data_input/Belaege_Gewichtung_Szenario1.csv",
delim = ";"
)
weights_s2_raw <- read_delim(
"01_data_input/Belaege_Gewichtung_Szenario2.csv",
delim = ";"
)
weights_s3_raw <- read_delim(
"01_data_input/Belaege_Gewichtung_Szenario3.csv",
delim = ";"
)2. Daten bereinigen und harmonisieren
Ziel: Daten für den Join und die MCA Berechnung vorbereiten.
# A. Bereinigung der Rohdaten (Belaege_normiert.csv)
df_belaege <- df_belaege_raw %>%
select(belagskategorie, option, everything())
# B. Bereinigung der Gewichtungen (ALLE SZENARIEN)
# Wir fügen den Roh-Dateien die Szenario-Namen hinzu
df_weights_s0 <- weights_s0_raw %>%
mutate(szenario = "Szenario 0: Baseline (IST)")
df_weights_s1 <- weights_s1_raw %>%
mutate(szenario = "Szenario 1: Forschungsfokus")
df_weights_s2 <- weights_s2_raw %>%
mutate(szenario = "Szenario 2: Radikale Vermeidung")
df_weights_s3 <- weights_s3_raw %>%
mutate(szenario = "Szenario 3: Radikaler Lebenszyklus")
# Jetzt binden wir sie zu einer finalen Gewichtungs-Tabelle zusammen
df_weights <- bind_rows(df_weights_s0, df_weights_s1, df_weights_s2, df_weights_s3) %>%
# Berechne das Gesamtgewicht (gewicht) aus den Rohspalten,
mutate(
gewicht = group_weight * within_group_weight
) %>%
# umbenennen für den Join
rename(
bewertungskategorie = criterion_id
) %>%
# Auswählen der Spalten, die der Rest des Skripts braucht
select(szenario, bewertungskategorie, gewicht, group_id)
print(df_weights, n = 48)# A tibble: 48 × 4
szenario bewertungskategorie gewicht group_id
<chr> <chr> <dbl> <chr>
1 Szenario 0: Baseline (IST) co2 0.05 umweltbela…
2 Szenario 0: Baseline (IST) graueEnergie 0.05 umweltbela…
3 Szenario 0: Baseline (IST) lebensdauer 0.2 langlebigk…
4 Szenario 0: Baseline (IST) unterhalt 0.1 langlebigk…
5 Szenario 0: Baseline (IST) kosten 0.1 langlebigk…
6 Szenario 0: Baseline (IST) versickerung 0.1 multifunkt…
7 Szenario 0: Baseline (IST) oberflaechentemperatur 0.1 multifunkt…
8 Szenario 0: Baseline (IST) befahrbarkeit 0.1 multifunkt…
9 Szenario 0: Baseline (IST) barrierefreiheit 0.1 multifunkt…
10 Szenario 0: Baseline (IST) recyclingfaehigkeit 0.0333 kreislauff…
11 Szenario 0: Baseline (IST) lokaleMaterialien 0.0333 kreislauff…
12 Szenario 0: Baseline (IST) modulareErneuerbarkeit 0.0333 kreislauff…
13 Szenario 1: Forschungsfokus co2 0.125 umweltbela…
14 Szenario 1: Forschungsfokus graueEnergie 0.125 umweltbela…
15 Szenario 1: Forschungsfokus lebensdauer 0.2 langlebigk…
16 Szenario 1: Forschungsfokus unterhalt 0.1 langlebigk…
17 Szenario 1: Forschungsfokus kosten 0.1 langlebigk…
18 Szenario 1: Forschungsfokus versickerung 0.025 multifunkt…
19 Szenario 1: Forschungsfokus oberflaechentemperatur 0.025 multifunkt…
20 Szenario 1: Forschungsfokus befahrbarkeit 0.025 multifunkt…
21 Szenario 1: Forschungsfokus barrierefreiheit 0.025 multifunkt…
22 Szenario 1: Forschungsfokus recyclingfaehigkeit 0.0833 kreislauff…
23 Szenario 1: Forschungsfokus lokaleMaterialien 0.0833 kreislauff…
24 Szenario 1: Forschungsfokus modulareErneuerbarkeit 0.0833 kreislauff…
25 Szenario 2: Radikale Vermeidung co2 0.225 umweltbela…
26 Szenario 2: Radikale Vermeidung graueEnergie 0.225 umweltbela…
27 Szenario 2: Radikale Vermeidung lebensdauer 0.025 langlebigk…
28 Szenario 2: Radikale Vermeidung unterhalt 0.0125 langlebigk…
29 Szenario 2: Radikale Vermeidung kosten 0.0125 langlebigk…
30 Szenario 2: Radikale Vermeidung versickerung 0.0125 multifunkt…
31 Szenario 2: Radikale Vermeidung oberflaechentemperatur 0.0125 multifunkt…
32 Szenario 2: Radikale Vermeidung befahrbarkeit 0.0125 multifunkt…
33 Szenario 2: Radikale Vermeidung barrierefreiheit 0.0125 multifunkt…
34 Szenario 2: Radikale Vermeidung recyclingfaehigkeit 0.150 kreislauff…
35 Szenario 2: Radikale Vermeidung lokaleMaterialien 0.150 kreislauff…
36 Szenario 2: Radikale Vermeidung modulareErneuerbarkeit 0.150 kreislauff…
37 Szenario 3: Radikaler Lebenszyklus co2 0.025 umweltbela…
38 Szenario 3: Radikaler Lebenszyklus graueEnergie 0.025 umweltbela…
39 Szenario 3: Radikaler Lebenszyklus lebensdauer 0.4 langlebigk…
40 Szenario 3: Radikaler Lebenszyklus unterhalt 0.2 langlebigk…
41 Szenario 3: Radikaler Lebenszyklus kosten 0.2 langlebigk…
42 Szenario 3: Radikaler Lebenszyklus versickerung 0.025 multifunkt…
43 Szenario 3: Radikaler Lebenszyklus oberflaechentemperatur 0.025 multifunkt…
44 Szenario 3: Radikaler Lebenszyklus befahrbarkeit 0.025 multifunkt…
45 Szenario 3: Radikaler Lebenszyklus barrierefreiheit 0.025 multifunkt…
46 Szenario 3: Radikaler Lebenszyklus recyclingfaehigkeit 0.0167 kreislauff…
47 Szenario 3: Radikaler Lebenszyklus lokaleMaterialien 0.0167 kreislauff…
48 Szenario 3: Radikaler Lebenszyklus modulareErneuerbarkeit 0.0167 kreislauff…3. Datentransformation
Ziel: Transformation der Tabelle df_belaege von Wide-to-Long und anschliessende Verknüpfung mit der Tabelle df_weights über join
# 3.1 Wide-to-Long: Transformation der Rohdaten
# Ziel: Die Kriterien-Spalten (z.B. lebensdauer, kosten) in Zeilen umwandeln,
# damit sie mit der Gewichtungstabelle verknüpft werden kann.
df_belaege_long <- df_belaege %>%
pivot_longer(
# Wählt alle Spalten von 'lebensdauer' bis 'barrierefreiheit' aus.
cols = c(lebensdauer:barrierefreiheit),
# Die Spaltennamen (z.B. "lebensdauer") kommen in die neue Spalte "bewertungskategorie".
names_to = "bewertungskategorie",
# Die Werte (z.B. 22.5) kommen in die neue Spalte "wert".
values_to = "wert"
)
# 3.2 JOIN: Verknüpfung der Long-Tabelle mit der Gewichtungstabelle
# Ziel: Jede Kriteriums-Zeile (z.B. "lebensdauer") mit ihrem
# entsprechenden Gewicht (z.B. 0.1) anreichern.
df_belaege_joined <- df_belaege_long %>%
# Verknüpft die 'df_belaege_long' (linke Tabelle) mit 'df_weights' (rechte Tabelle).
# Die Verknüpfung ("der Schlüssel") ist die Spalte "bewertungskategorie",
# die jetzt in beiden Tabellen identisch heisst.
left_join(df_weights, by = "bewertungskategorie",# Diese Zeile sagt R, dass wir den Many-to-Many-Join erwarten
relationship = "many-to-many"
)4. Explorative Datenanalyse
Ziel: Die Verteilung der Rohwerte pro Kriterium ansehen. Dies zeigt, warum eine Normierung (Block 4) zwingend notwendig ist, da die Skalen (Jahre, CHF, kg) völlig unterschiedlich sind.
# Boxplot der Rohwerte
plot_rohwerte <- ggplot(df_belaege_joined, aes(x = bewertungskategorie, y = wert)) +
geom_boxplot() +
# coord_flip() dreht die Achsen, damit die Namen lesbar sind
coord_flip() +
labs(
title = "Verteilung der Rohwerte (vor Normierung)",
subtitle = "Zeigt die unterschiedlichen Skalen (Einheiten) der Kriterien",
x = "Kriterium",
y = "Wert (gemischte Einheiten)"
) +
theme_minimal()
print(plot_rohwerte)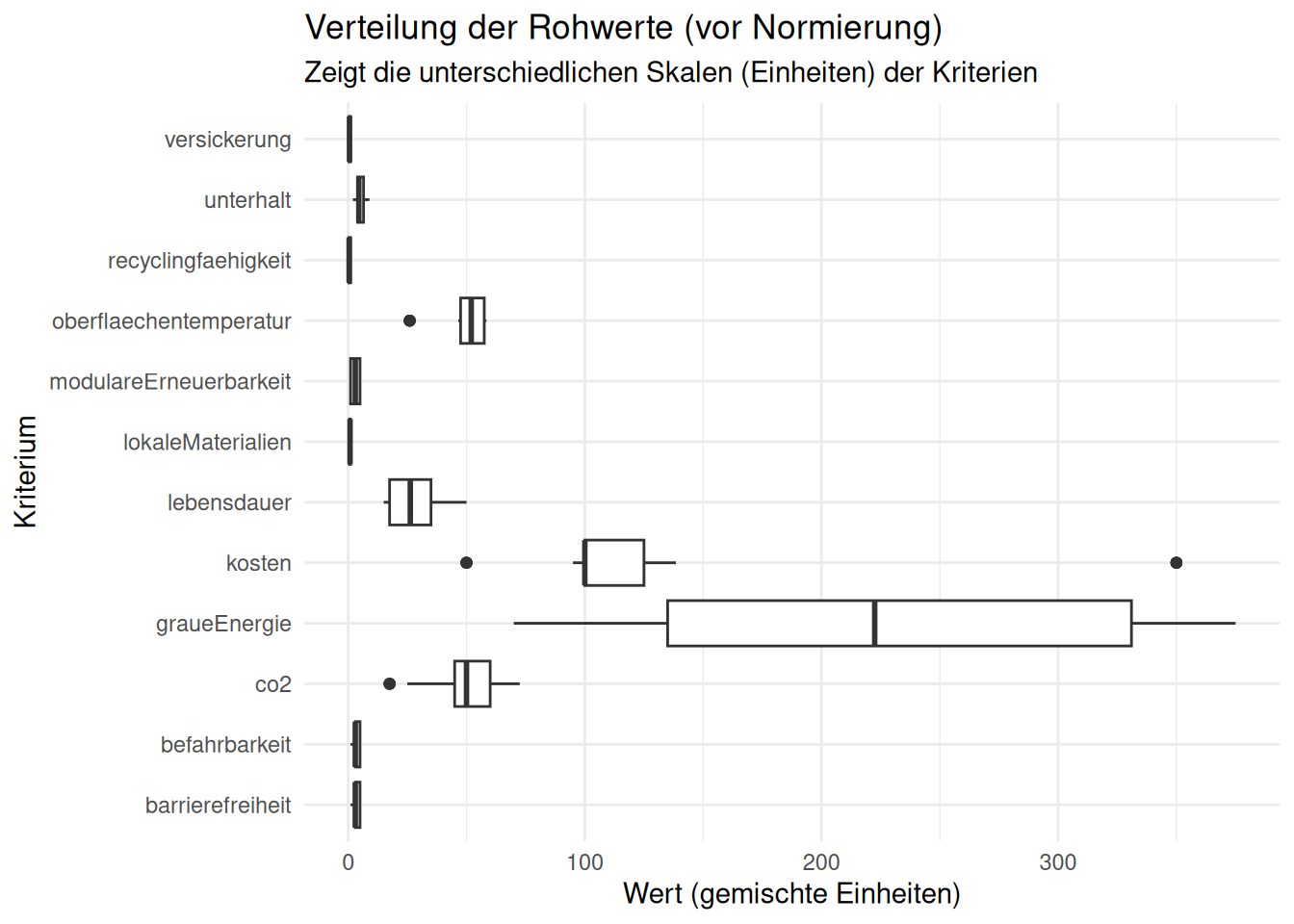
ggsave("02_export/plots/check_01_rohwerte_verteilung.png", plot = plot_rohwerte, width = 10, height = 7)5. MCA - Normalisierung
Ziel: -Normalisierung: Die Wert-Spalte (Jahre, CHF, etc.) muss auf eine einheitliche Skala (0-1) gebracht werden -Wie gut ist der entsprechende Belag im entsprechenden Kriterium im Vergleich zu allen anderen Belägen? (Min-Max-Skalierung)
# 5.1 Definieren, welche Kriterien 'schlechter' sind, wenn sie 'höher' sind
kriterien_lower_is_better <- c(
"kosten",
"unterhalt",
"co2",
"graueEnergie",
"oberflaechentemperatur"
)
# 5.2 Min-Max-Skalierung (Normierung)
# Aufgeteilt in zwei Schritte für die Überprüfung
# Schritt 5.2a: Min/Max-Werte berechnen und in einer Zwischentabelle speichern
df_belaege_with_minmax <- df_belaege_joined %>%
filter(!is.na(wert)) %>% # NAs im Wert ignorieren
filter(!is.na(gewicht)) %>% # NAs im Gewicht ignorieren (wichtig!)
group_by(bewertungskategorie) %>%
# 1. Min und Max für jedes Kriterium finden
mutate(
min_wert = min(wert, na.rm = TRUE),
max_wert = max(wert, na.rm = TRUE)
) %>%
ungroup()
# Überprüfung der Min/Max-Werte: Erstellt eine kleine, saubere Tabelle, die nur die Min/Max-Werte zeigt
df_min_max_summary <- df_belaege_with_minmax %>%
select(bewertungskategorie, min_wert, max_wert) %>%
distinct() # Zeigt jede Kategorie nur einmal an
print("--- Min/Max-Werte pro Kriterium (für Normierung) ---")[1] "--- Min/Max-Werte pro Kriterium (für Normierung) ---"print(df_min_max_summary)# A tibble: 12 × 3
bewertungskategorie min_wert max_wert
<chr> <dbl> <dbl>
1 lebensdauer 15 50
2 versickerung 0.2 1
3 oberflaechentemperatur 26 58.4
4 befahrbarkeit 1 5
5 kosten 50 350
6 unterhalt 2 9
7 co2 17.5 72.5
8 graueEnergie 70 375
9 recyclingfaehigkeit 0.2 1
10 lokaleMaterialien 0.4 1
11 modulareErneuerbarkeit 1 5
12 barrierefreiheit 1 5 # --------------------------------------------------------
# Schritt 5.2b: Skalierung auf 0-1 berechnen
# Wir nehmen die Tabelle aus 5.2a und rechnen weiter
df_belaege_normalized <- df_belaege_with_minmax %>%
# 2. Skalieren auf 0-1
mutate(
# Sonderfall: Wenn Min und Max gleich sind (nur ein Wert), setze Score auf 1
score_normiert = case_when(
(max_wert - min_wert) == 0 ~ 1,
# Normale Skalierung (higher is better), ! bedeutet NICHT in kriterien_lower_is_better Liste enthalten
!(bewertungskategorie %in% kriterien_lower_is_better) ~ (wert - min_wert) / (max_wert - min_wert),
# Invertierte Skalierung (lower is better)
bewertungskategorie %in% kriterien_lower_is_better ~ 1 - ((wert - min_wert) / (max_wert - min_wert))
)
)6. Explorative Datenanalyse
Ziel: Überprüfen, ob die Min-Max-Skalierung (Block 5.2) funktioniert hat.
# Boxplot der normierten Scores
plot_normiert <- ggplot(df_belaege_normalized, aes(x = bewertungskategorie, y = score_normiert)) +
geom_boxplot() +
coord_flip() +
# Setzt die Y-Achse fix auf 0 bis 1
scale_y_continuous(limits = c(0, 1)) +
labs(
title = "Verteilung der normierten Scores (nach Normierung)",
subtitle = "Qualitätskontrolle: Alle Kriterien sollten jetzt auf 0-1 skaliert sein.",
x = "Kriterium",
y = "Normierter Score (0-1)"
) +
theme_minimal()
print(plot_normiert)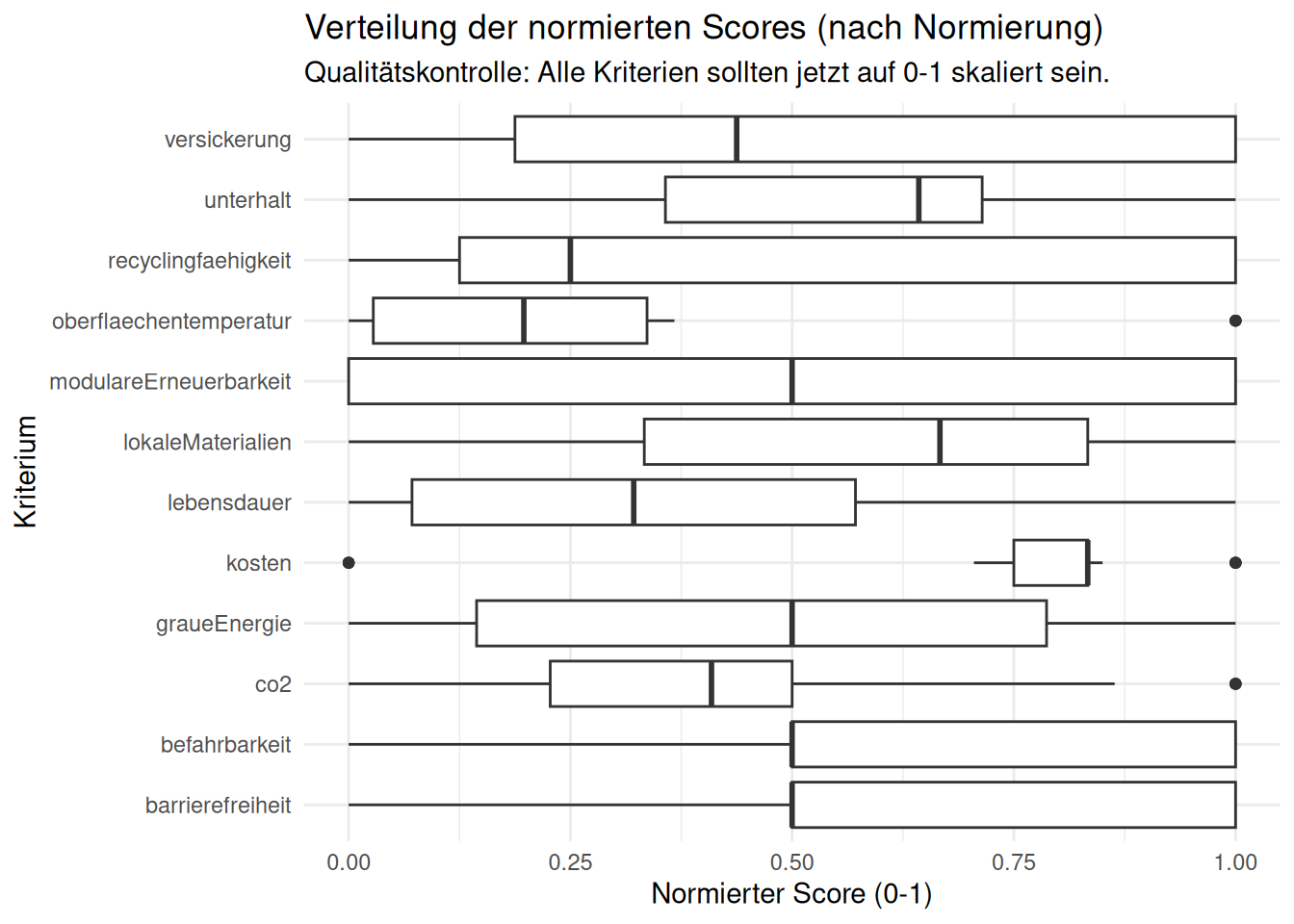
ggsave("02_export/plots/check_02_normierte_scores.png", plot = plot_normiert, width = 10, height = 7)7. MCA Berechnung
Ziel: Berechnung der besten geeigneten Beläge auf Basis Kriterienbewertung (score_normiert * gewicht)
# 7.1 Berechnung des gewichteten Scores
# (Keine Änderung hier, 'gewicht' ist jetzt pro Szenario unterschiedlich)
df_mca_calculated <- df_belaege_normalized %>%
mutate(
MCA_score_kriterium = score_normiert * gewicht
)
# 7.2 Aggregation
# Wir gruppieren jetzt AUCH nach 'szenario'
df_mca_total <- df_mca_calculated %>%
group_by(szenario, belagskategorie, option) %>% # <-- 'szenario' hinzugefügt
summarise(
MCA_gesamtscore = sum(MCA_score_kriterium, na.rm = TRUE)
) %>%
ungroup() %>%
# Wir sortieren erst nach Szenario, dann nach Score
arrange(szenario, desc(MCA_gesamtscore))
# Anzeigen der Ergebnisse (jetzt 40 Zeilen, 10 pro Szenario)
print("--- MCA Gesamtergebnis (sortiert) ---")[1] "--- MCA Gesamtergebnis (sortiert) ---"print(df_mca_total, n = 40) # n=40, um alle Ergebnisse zu sehen# A tibble: 40 × 4
szenario belagskategorie option MCA_gesamtscore
<chr> <chr> <chr> <dbl>
1 Szenario 0: Baseline (IST) Pflaster Betonpfla… 0.666
2 Szenario 0: Baseline (IST) Asphalt Selbsthei… 0.633
3 Szenario 0: Baseline (IST) Asphalt Recycling… 0.573
4 Szenario 0: Baseline (IST) Pflaster Naturstei… 0.536
5 Szenario 0: Baseline (IST) Asphalt Heller As… 0.522
6 Szenario 0: Baseline (IST) Sickerbeläge Rasengitt… 0.519
7 Szenario 0: Baseline (IST) Sickerbeläge Chaussier… 0.471
8 Szenario 0: Baseline (IST) Pflaster Ökopflast… 0.451
9 Szenario 0: Baseline (IST) Asphalt Sickerasp… 0.348
10 Szenario 0: Baseline (IST) Sickerbeläge Kiesrasen 0.330
11 Szenario 1: Forschungsfokus Sickerbeläge Chaussier… 0.712
12 Szenario 1: Forschungsfokus Pflaster Betonpfla… 0.636
13 Szenario 1: Forschungsfokus Pflaster Naturstei… 0.541
14 Szenario 1: Forschungsfokus Sickerbeläge Kiesrasen 0.520
15 Szenario 1: Forschungsfokus Pflaster Ökopflast… 0.518
16 Szenario 1: Forschungsfokus Sickerbeläge Rasengitt… 0.517
17 Szenario 1: Forschungsfokus Asphalt Recycling… 0.462
18 Szenario 1: Forschungsfokus Asphalt Selbsthei… 0.417
19 Szenario 1: Forschungsfokus Asphalt Heller As… 0.351
20 Szenario 1: Forschungsfokus Asphalt Sickerasp… 0.298
21 Szenario 2: Radikale Vermeidung Sickerbeläge Chaussier… 0.922
22 Szenario 2: Radikale Vermeidung Sickerbeläge Kiesrasen 0.768
23 Szenario 2: Radikale Vermeidung Pflaster Betonpfla… 0.604
24 Szenario 2: Radikale Vermeidung Pflaster Ökopflast… 0.569
25 Szenario 2: Radikale Vermeidung Sickerbeläge Rasengitt… 0.551
26 Szenario 2: Radikale Vermeidung Pflaster Naturstei… 0.484
27 Szenario 2: Radikale Vermeidung Asphalt Recycling… 0.402
28 Szenario 2: Radikale Vermeidung Asphalt Heller As… 0.253
29 Szenario 2: Radikale Vermeidung Asphalt Sickerasp… 0.176
30 Szenario 2: Radikale Vermeidung Asphalt Selbsthei… 0.103
31 Szenario 3: Radikaler Lebenszyklus Asphalt Selbsthei… 0.733
32 Szenario 3: Radikaler Lebenszyklus Pflaster Betonpfla… 0.667
33 Szenario 3: Radikaler Lebenszyklus Pflaster Naturstei… 0.608
34 Szenario 3: Radikaler Lebenszyklus Sickerbeläge Chaussier… 0.517
35 Szenario 3: Radikaler Lebenszyklus Asphalt Recycling… 0.508
36 Szenario 3: Radikaler Lebenszyklus Sickerbeläge Rasengitt… 0.478
37 Szenario 3: Radikaler Lebenszyklus Pflaster Ökopflast… 0.473
38 Szenario 3: Radikaler Lebenszyklus Asphalt Heller As… 0.431
39 Szenario 3: Radikaler Lebenszyklus Asphalt Sickerasp… 0.428
40 Szenario 3: Radikaler Lebenszyklus Sickerbeläge Kiesrasen 0.2738. Darstellung
Ziel: visualisierung der Ergebnisse
# Plot 1: Gesamtergebnis (Ranking)
plot_mca_total <- ggplot(df_mca_total,
aes(x = MCA_gesamtscore,
y = tidytext::reorder_within(option, MCA_gesamtscore, szenario),
fill = belagskategorie)) +
geom_col() +
tidytext::scale_y_reordered() +
# facet_wrap erstellt automatisch ein 2x2 Grid für die 4 Szenarien
facet_wrap(~ szenario, scales = "free_y") +
labs(
title = "MCA Ergebnis: Rangliste der Belagsoptionen nach Szenario",
subtitle = "Höherer Score = Bessere Gesamtbewertung (pro Szenario sortiert)",
x = "MCA Gesamtscore",
y = "Belagsoption",
fill = "Belagskategorie"
) +
theme_minimal() +
theme(legend.position = "top")
print(plot_mca_total)
# --- ANGEPASSTE DIMENSIONEN (für 2x2 Grid) ---
ggsave("02_export/plots/mca_gesamtergebnis_alle_szenarien.png",
plot = plot_mca_total, width = 12, height = 10)
# --------------------------------------------
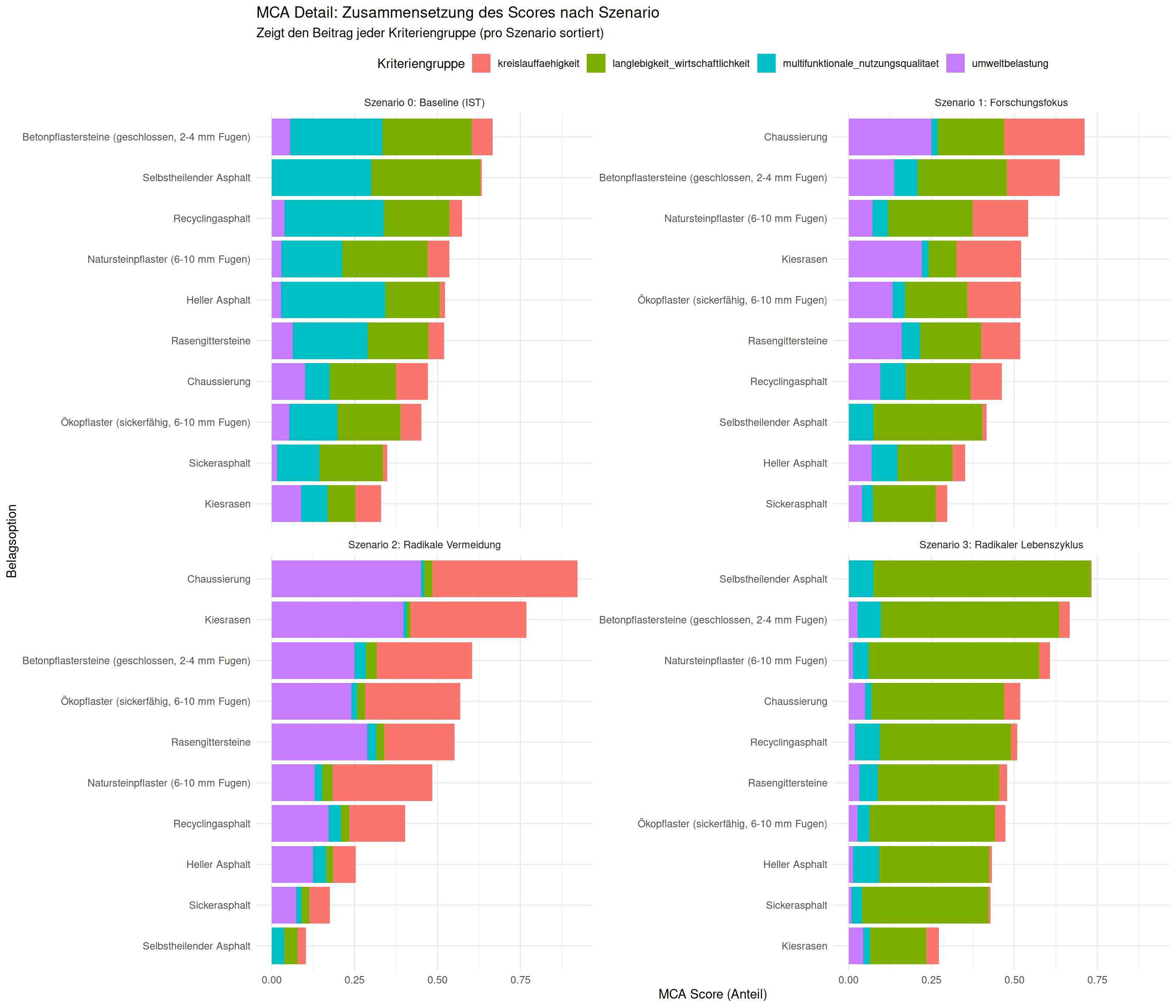
# Plot 2: Detail-Zusammensetzung (Gestapeltes Diagramm)
# 1. Daten vorbereiten
df_mca_groups <- df_mca_calculated %>%
group_by(szenario, belagskategorie, option, group_id) %>%
summarise(gruppen_score = sum(MCA_score_kriterium, na.rm = TRUE)) %>%
ungroup() %>%
left_join(df_mca_total, by = c("szenario", "belagskategorie", "option"))
# 2. Gestapeltes Diagramm plotten
plot_mca_stacked <- ggplot(df_mca_groups,
aes(x = gruppen_score,
y = tidytext::reorder_within(option, MCA_gesamtscore, szenario),
fill = group_id)) +
geom_col(position = "stack") +
tidytext::scale_y_reordered() +
# facet_wrap erstellt automatisch ein 2x2 Grid
facet_wrap(~ szenario, scales = "free_y") +
labs(
title = "MCA Detail: Zusammensetzung des Scores nach Szenario",
subtitle = "Zeigt den Beitrag jeder Kriteriengruppe (pro Szenario sortiert)",
x = "MCA Score (Anteil)",
y = "Belagsoption",
fill = "Kriteriengruppe"
) +
theme_minimal() +
theme(legend.position = "top")
print(plot_mca_stacked)
# --- ANGEPASSTE DIMENSIONEN (für 2x2 Grid) ---
ggsave("02_export/plots/mca_detail_gruppen_alle_szenarien.png",
plot = plot_mca_stacked, width = 14, height = 10)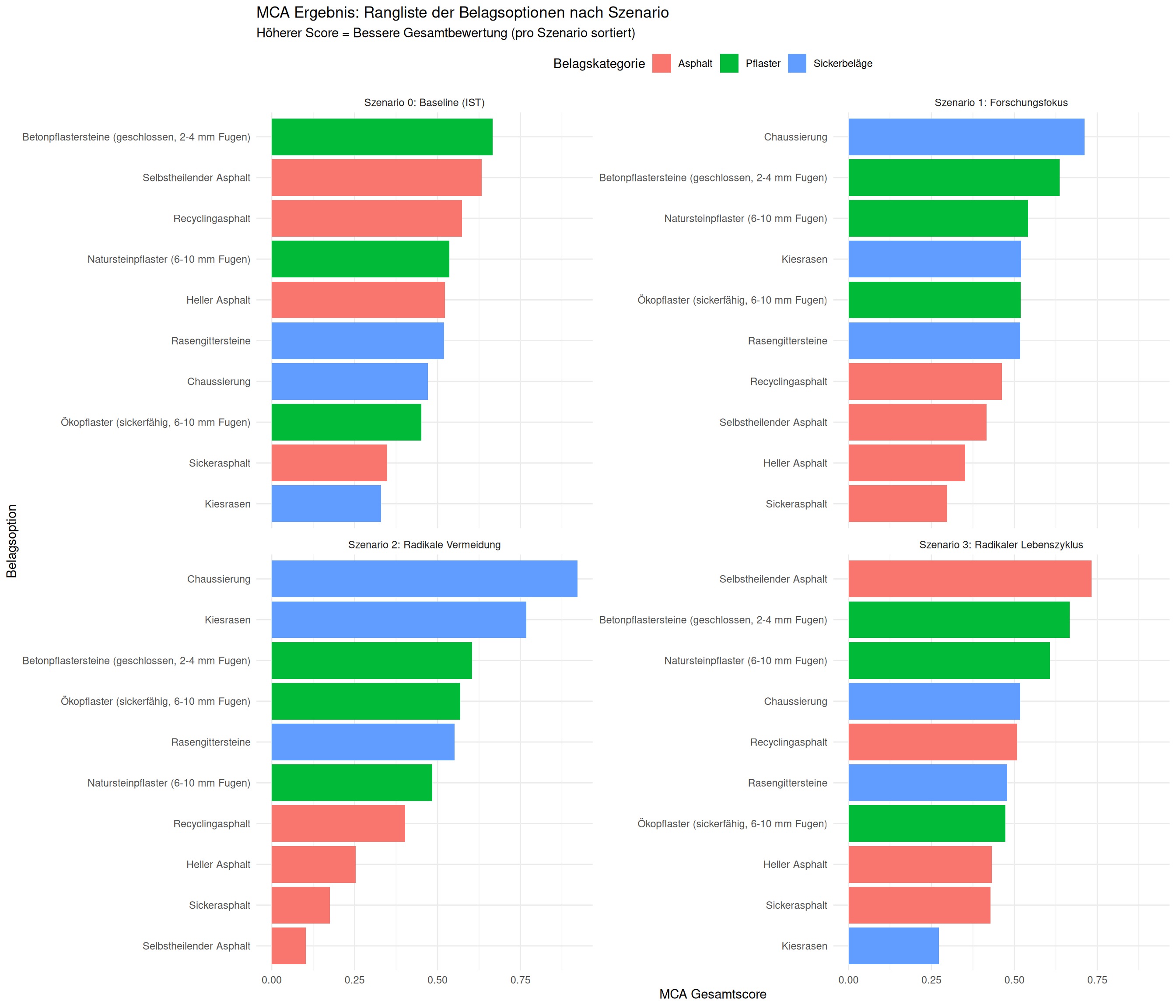
9. Ergebnisstabellen exportieren
# 1. Speichern der finalen MCA-Rangliste (alle 30 Zeilen)
write_csv2(
df_mca_total,
file = "02_export/tables/mca_rangliste_alle_szenarien.csv"
)
# 2. Speichern der kompletten Berechnungs-Details (alle 360+ Zeilen)
write_csv2(
df_mca_calculated,
file = "02_export/tables/mca_details_berechnung_alle_szenarien.csv"
)